Generative Adversarial Networks (GANs)
GANs are at the heart of our synthetic data generation process. GANs consist of two neural networks – a generator and a discriminator – continuously engaged in a competition. The generator strives to produce data that is indistinguishable from real-world data, while the discriminator diligently assesses its authenticity. This adversarial training results in a dynamic feedback loop that pushes the generator to continually refine its creations. The outcome? Synthetic data that not only mimics the statistical properties of real data but also exhibits the nuances and complexities essential for training AI models effectively.

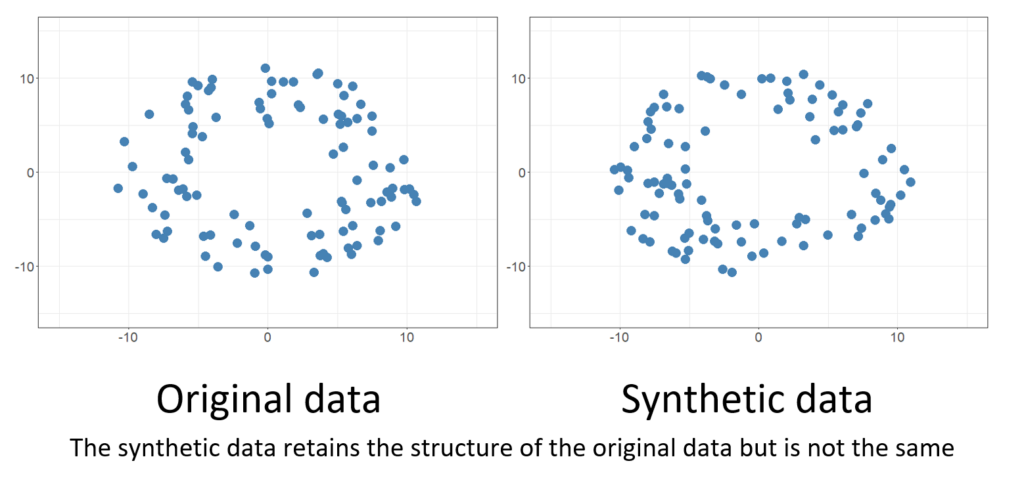
Variational Autoencoders (VAEs)
Complementing GANs, Variational Autoencoders (VAEs) play a crucial role in our synthetic data generation pipeline. VAEs excel at capturing the underlying structure and distribution of data. They do so by learning a compact representation, or latent space, where data can be manipulated and generated with precision. VAEs allow us to generate synthetic data that adheres not only to the statistical patterns but also the finer-grained features and relationships present in real data. This level of fidelity is essential for training AI models that generalize well and excel in real-world scenarios.